テキストの有害度をスコア化できるGoogleのPerspective APIをPythonで使う手順

Photo by Franki Chamaki on Unsplash
はじめに
GoogleのプロジェクトとしてJigsawというものがあります。Jigsawでは、「どうしたらテクノロジーで世界中の人々に安全をもたらせるのか?」をコンセプトとして色々なプロジェクトが展開されています。そしてその中の1つに、「オンラインでの嫌がらせから人々を守るには」というメッセージのもと進められているのがPerspectiveというプロジェクトです。このPerspectiveではAPIが用意されており、与えられた文字列がどれぐらい有害であるかを色々な指標でスコア化することができます。この記事では、このPerspective APIをPythonで実際に動かしてみるところまでの手順をまとめます。
できるようになること
与えた英語の文字列がどれぐらい有害であるかをスコア表示します。例えば、Hello, everyone! Nice to meet you.という文字列のTOXICITY(毒性)スコアを以下のようにJSON形式で取得できます。以下では、Hello, everyone! Nice to meet you.のTOXICITYが0.04と低いことを示しています。全てのスコアは0〜1のスコアになります。他の指標もスコア化できます。なお日本語はまだ対応していないため、英語を対象としています。
{
"attributeScores": {
"TOXICITY": {
"spanScores": [
{
"begin": 0,
"end": 34,
"score": {
"value": 0.04011109,
"type": "PROBABILITY"
}
}
],
"summaryScore": {
"value": 0.04011109,
"type": "PROBABILITY"
}
}
},
"languages": [
"en"
]
}
前提と環境
以下の通りです。
- OS : Ubuntu18.04
- PythonとAnaconda、もしくはpipはインストール済とする
機械学習やデータ解析に触れる機会があり、今更ながら今後も必要になりそうなためまずはPythonを実行できる環境を構築しようと思いAnacondaをUbuntuにインストールしました。Anacondaをインストールすることで、PythonとJupyter Notebookの環境を構築できます。ここではその手順をメモします。
以降の手順は、以下のPerspective APIの公式ドキュメントに従って行います。
Perspective APIを有効化する
はじめに、Goolge APIsの管理画面からPerspective APIを有効化し、APIキーを取得する必要があります。 Googleアカウントにログインし、こちらのPerspective APIにアクセスします。Googleアカウントにログインしていない場合はログイン画面が表示されますのでログインします。
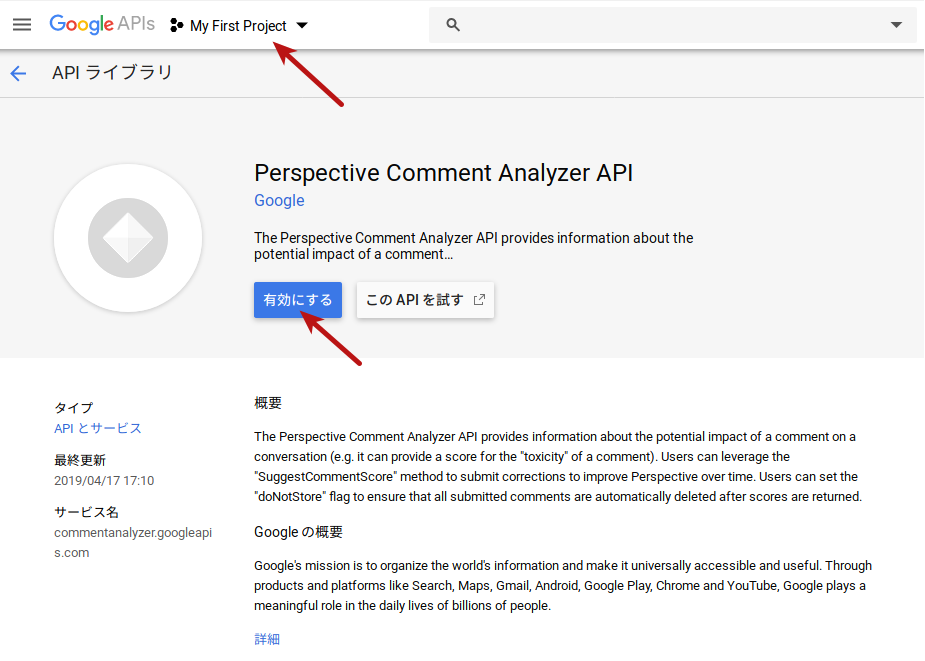
アクセスすると以下のようなページが表示されますので「有効にする」をクリックします。もしはじめてGoogle APIsにアクセスした場合は以下の画面が表示されないかもしれませんが、その場合については後述します。
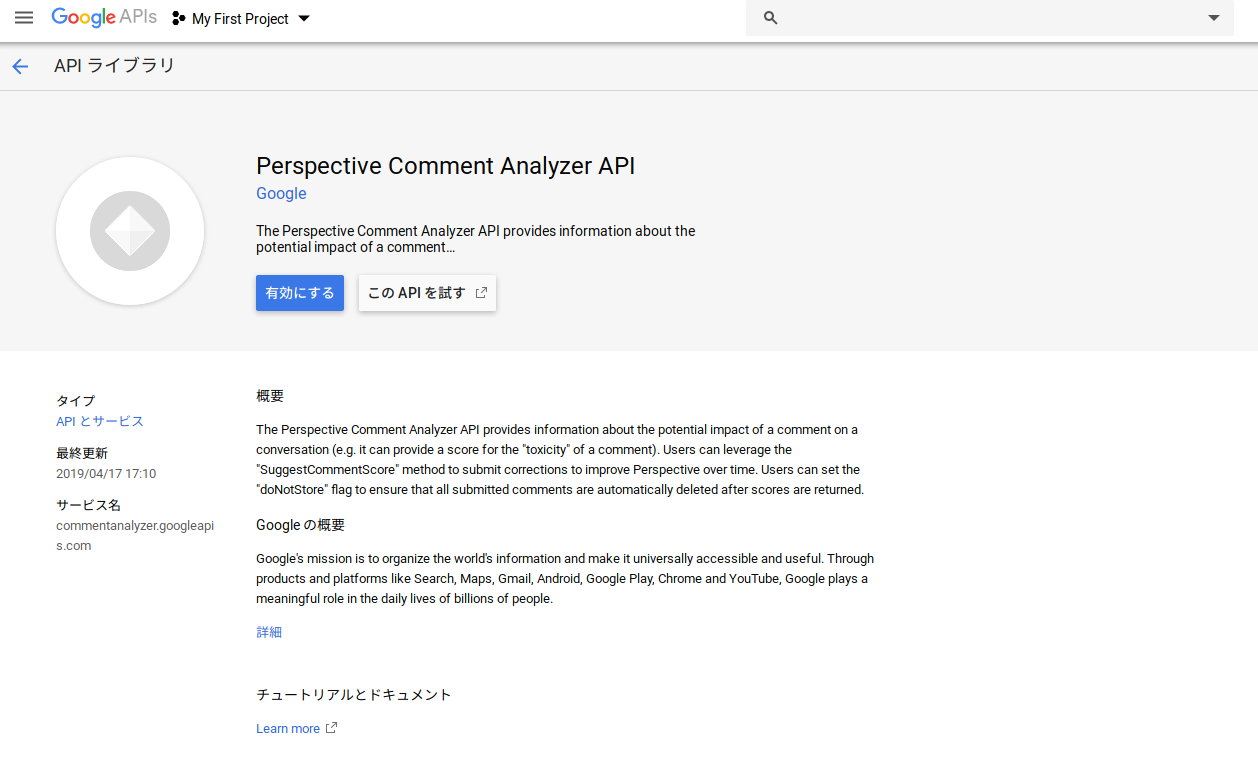
有効化後、APIキーを作成します。
はじめてGoogle APIsにアクセスした場合
この場合は少しだけ手順が異なります。必要な方は以下のボタンで展開して確認してみてください。 はじめてGoogle APIsにアクセスした場合の手順
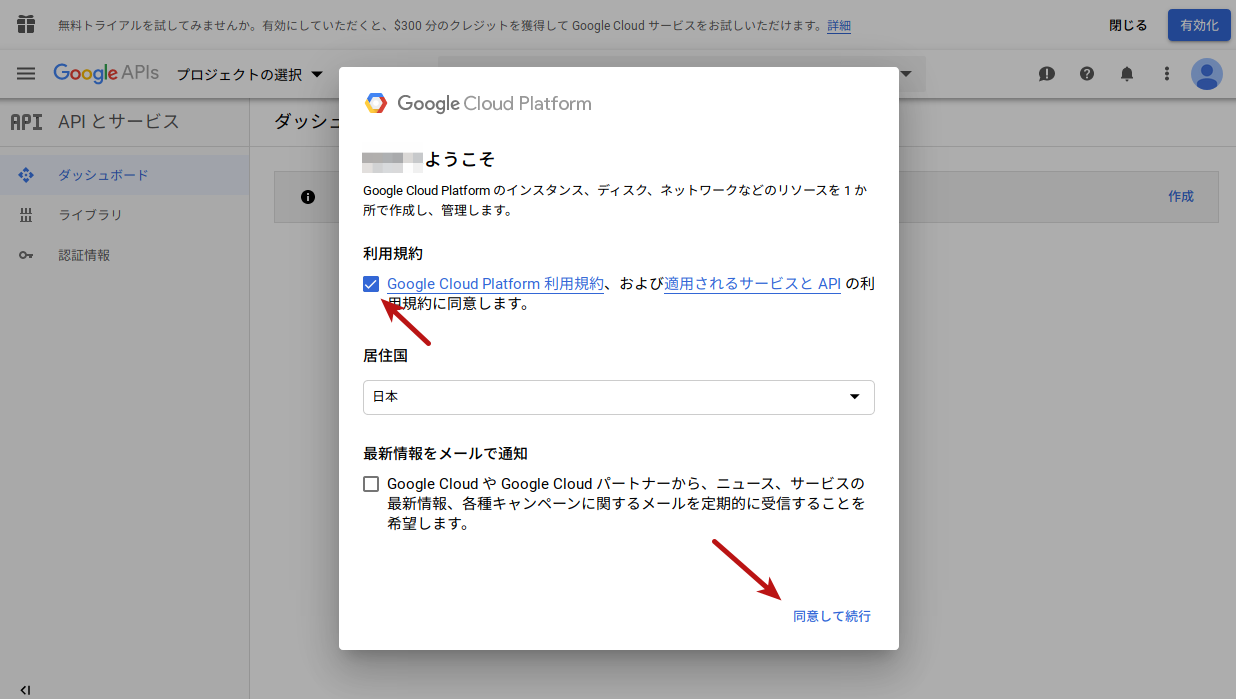
「同意して続行」をクリックすると、以下のようにダッシュボードが表示されますので、左側のメニューから「ライブラリ」をクリックします。
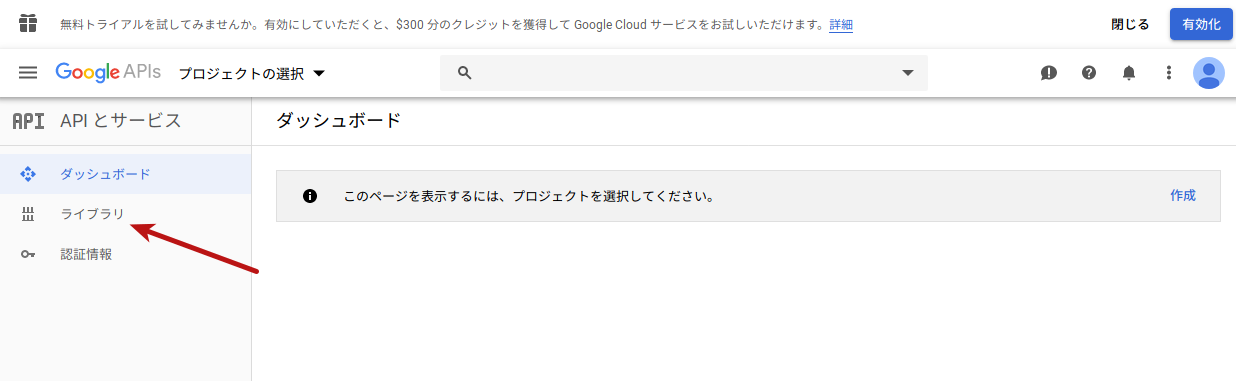
ライブラリの検索画面が表示されますので、以下のように「perspective」と入力します。検索結果に出てくる「Perspective Comment Analyzer API」をクリックします。
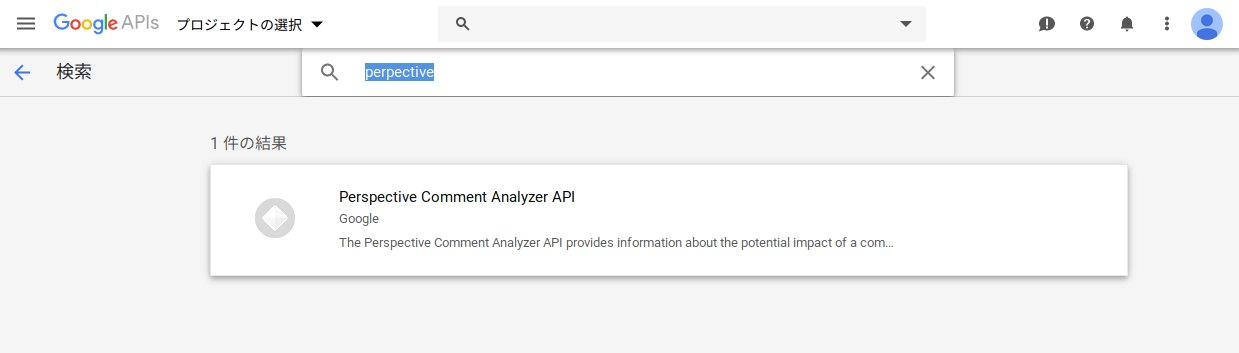
これで以下のように目的のPerspective APIの画面が表示されますので、前述した手順で有効化します。
ダッシュボードに移動すると、まずプロジェクトを作成するよう表示されるので作成します。
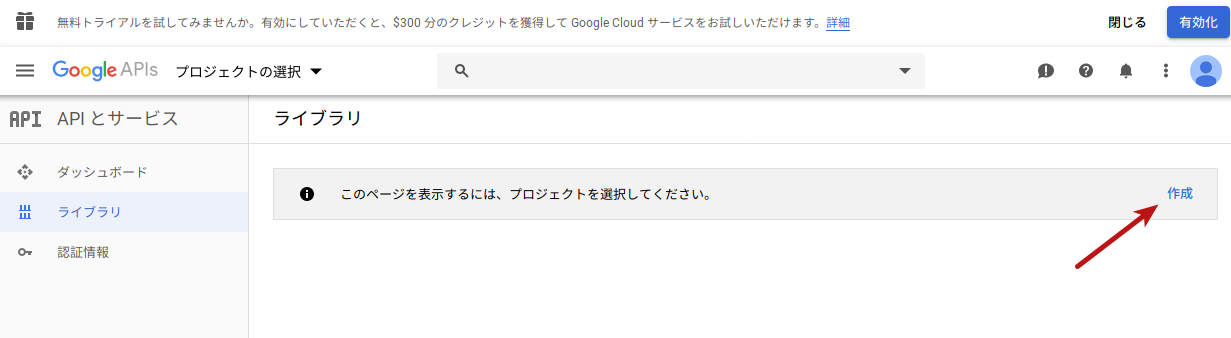
以下のように適当なプロジェクト名を入力し、各自の状況に合わせて「場所」を選択します。その後「作成」をクリックします。
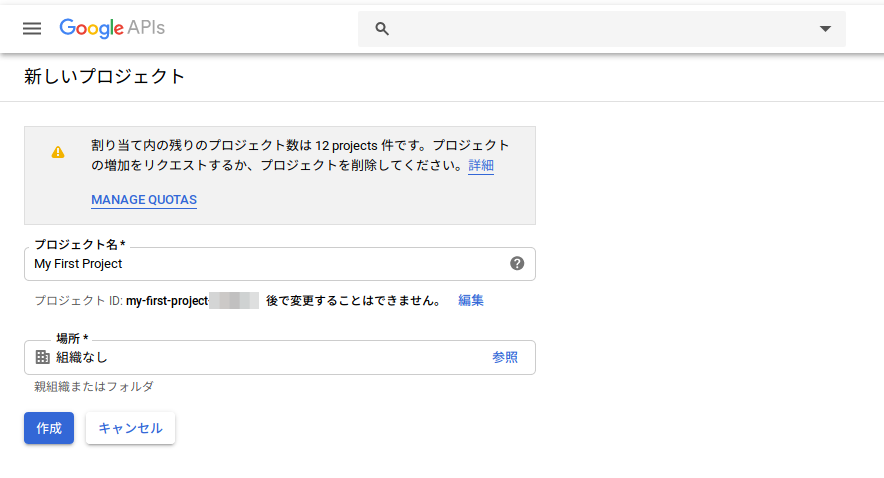
あとは以下のように作成したプロジェクトが選択されている状態で任意のAPIを有効化します。
APIキーを作成する
Google APIsのダッシュボードの左側メニューから「認証情報」をクリックし、以下のように「認証情報を作成」→「APIキー」をクリックします。
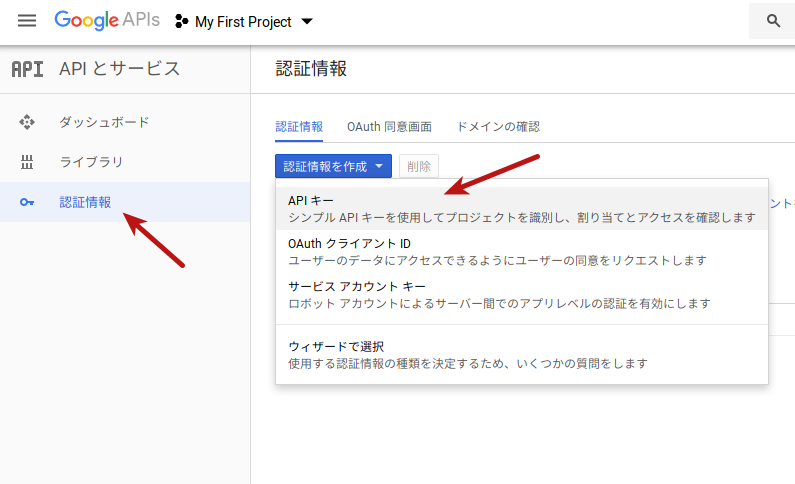
これまでに1つもAPIキーなどの認証情報を作成したことがない場合は以下のような表示になりますが作業は同じです。
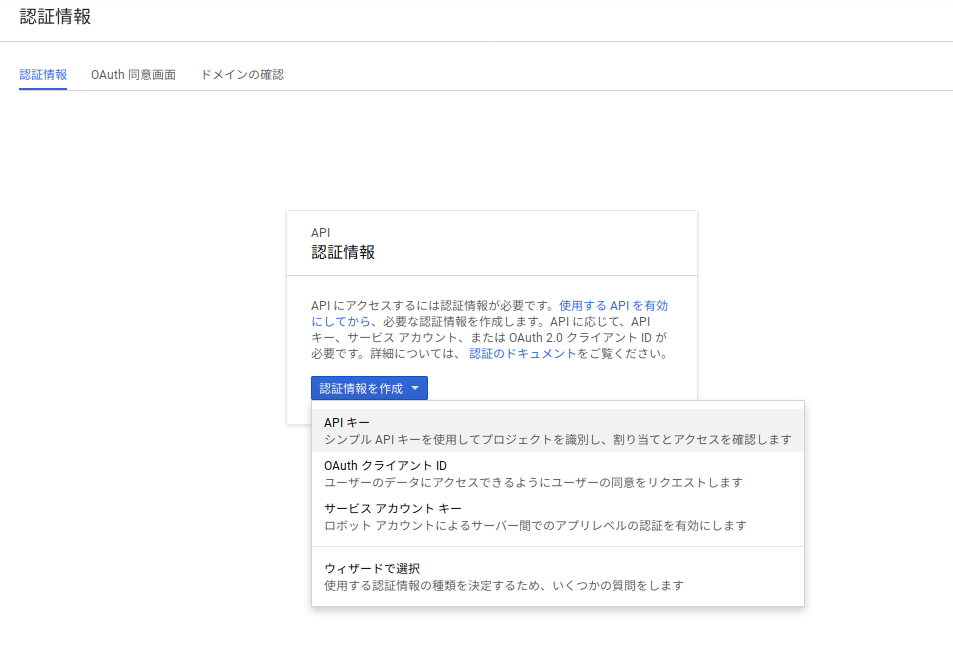
以下のようにAPIキーが作成されます。このAPIキーを後ほど使用しますのでメモしておきます。続いて作成したAPIキーの設定を行うために「キーを制限」をクリックします。
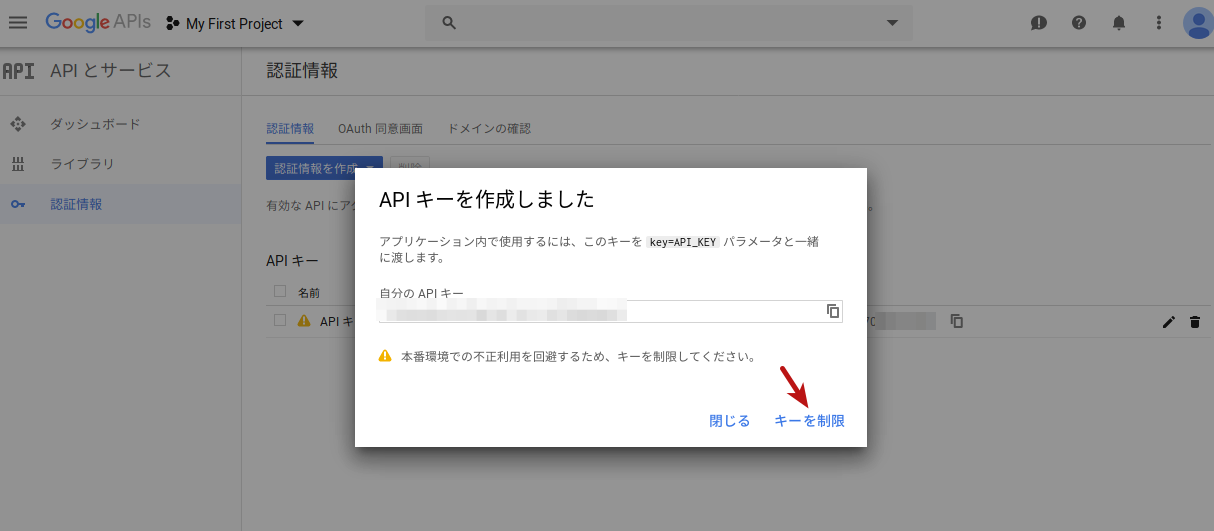
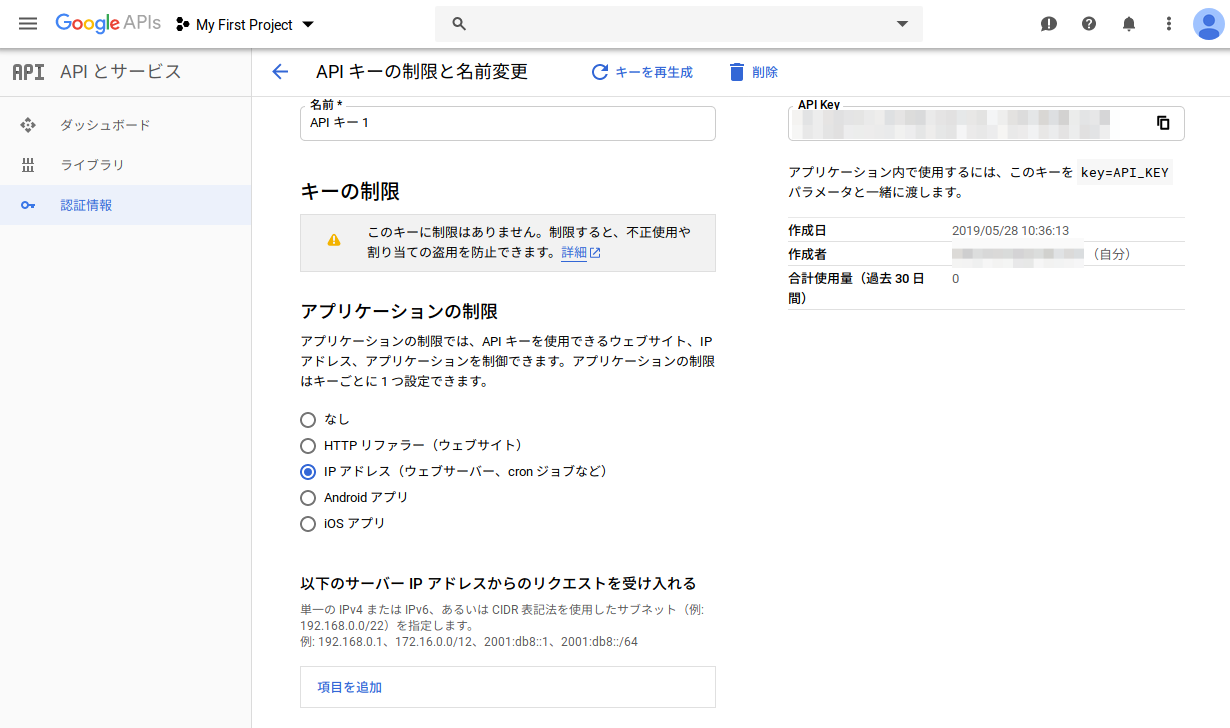
以下のように、作成したAPIキーについていくつか制限を設定することができます。例えば、このAPIキーへのアクセス元IPアドレスを制限したり、このAPIキーで使用できるAPIを選択することができます。
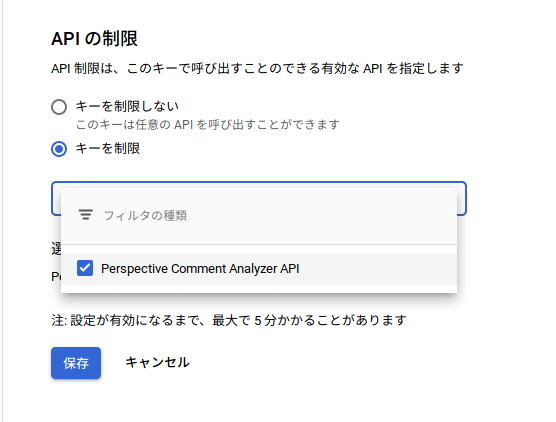
制限を設けない場合は、1つのAPIキーでこれまでに有効化したGoogleのAPIサービスを全て使用できてしまいますが以下のようにそのAPIキーでどのAPIを利用できるかを制限できます。
condaでGoogle API Python Clientをインストールする
Perspective APIをPythonからアクセスするには、まずPythonからGoogleのAPIにアクセスするためのクライアント用ライブラリをインストールする必要があります。インストールはとても簡単で、Anaconda環境であれば以下のcondaコマンドでインストールすることができます。
$ conda install -c conda-forge google-api-python-client
pipの場合は以下となります。
$ pip install --upgrade google-api-python-client
詳細は以下の公式ドキュメントに記載されています。
The official Python client library for Google's discovery based APIs
後は実際にPythonから使用します。
与えたテキストの有害度をスコア化するサンプルプログラム
これは公式ドキュメントにも記載されているサンプルです。以下コード内のYOUR_API_KEYは各自のAPIキーに置き換えてください。以下は、Hello, everyone! Nice to meet you.という内容をスコア化します。
from googleapiclient import discovery
API_KEY='YOUR_API_KEY'
# Generates API client object dynamically based on service name and version.
service = discovery.build('commentanalyzer', 'v1alpha1', developerKey=API_KEY)
analyze_request = {
'comment': { 'text': 'Hello, everyone! Nice to meet you.' },
'requestedAttributes': {
'TOXICITY': {}
}
}
response = service.comments().analyze(body=analyze_request).execute()
import json
print(json.dumps(response, indent=2))
上記を適当なファイルに保存してターミナルで実行します。ここではファイル名をperspective-test.pyとしました。
$ python perspective-test.py
以下の結果が返ってきます。
{
"attributeScores": {
"TOXICITY": {
"spanScores": [
{
"begin": 0,
"end": 34,
"score": {
"value": 0.04011109,
"type": "PROBABILITY"
}
}
],
"summaryScore": {
"value": 0.04011109,
"type": "PROBABILITY"
}
}
},
"languages": [
"en"
]
}
上記から、与えた文字列であるHello, everyone! Nice to meet you.のTOXICITYスコアが0.04011109と非常に小さいことが分かります。TOXICITYとは直訳すると毒性という意味です。すなわち、どれぐらい有害であるかという指標になります。ここでの有害というのは、例えば誹謗中傷など人にとっての有害です。
なお、Perspective APIでは、TOXICITY以外にもいくつかの指標をスコア化することができます。他の指標については公式ドキュメントに記載されています。
複数の指標をスコア化する
以下のようにいくつかの指標をまとめて指定してスコア化することができます。以下では、You are so stupid and useless.という内容について、TOXICITY以外にもPROFANITY(冒涜)、INSULT(侮辱)、INCOHERENT(一貫性)を指標として指定した例です。
from googleapiclient import discovery
API_KEY='YOUR_API_KEY'
# Generates API client object dynamically based on service name and version.
service = discovery.build('commentanalyzer', 'v1alpha1', developerKey=API_KEY)
analyze_request = {
'comment': { 'text': 'You are so stupid and useless.' },
'requestedAttributes': {
'TOXICITY': {},
'INSULT' : {},
'PROFANITY' : {},
'INCOHERENT' : {}
}
}
response = service.comments().analyze(body=analyze_request).execute()
import json
print(json.dumps(response, indent=2))
実行結果は以下のようになりました。
{
"attributeScores": {
"PROFANITY": {
"spanScores": [
{
"begin": 0,
"end": 30,
"score": {
"value": 0.85892,
"type": "PROBABILITY"
}
}
],
"summaryScore": {
"value": 0.85892,
"type": "PROBABILITY"
}
},
"INSULT": {
"spanScores": [
{
"begin": 0,
"end": 30,
"score": {
"value": 0.9811452,
"type": "PROBABILITY"
}
}
],
"summaryScore": {
"value": 0.9811452,
"type": "PROBABILITY"
}
},
"TOXICITY": {
"spanScores": [
{
"begin": 0,
"end": 30,
"score": {
"value": 0.979235,
"type": "PROBABILITY"
}
}
],
"summaryScore": {
"value": 0.979235,
"type": "PROBABILITY"
}
},
"INCOHERENT": {
"spanScores": [
{
"begin": 0,
"end": 30,
"score": {
"value": 0.033226248,
"type": "PROBABILITY"
}
}
],
"summaryScore": {
"value": 0.033226248,
"type": "PROBABILITY"
}
}
},
"languages": [
"en"
]
}
なお、与えられた文字列に複数の文章が含まれる場合には、それぞれに対してスコアを出します。そしてそれの総合点となるものがsummaryScoreです。ただし、文章が複数含まれていてもどこで区切るかは毎回同じとは限らないそうです。
Perspective APIの使用回数制限
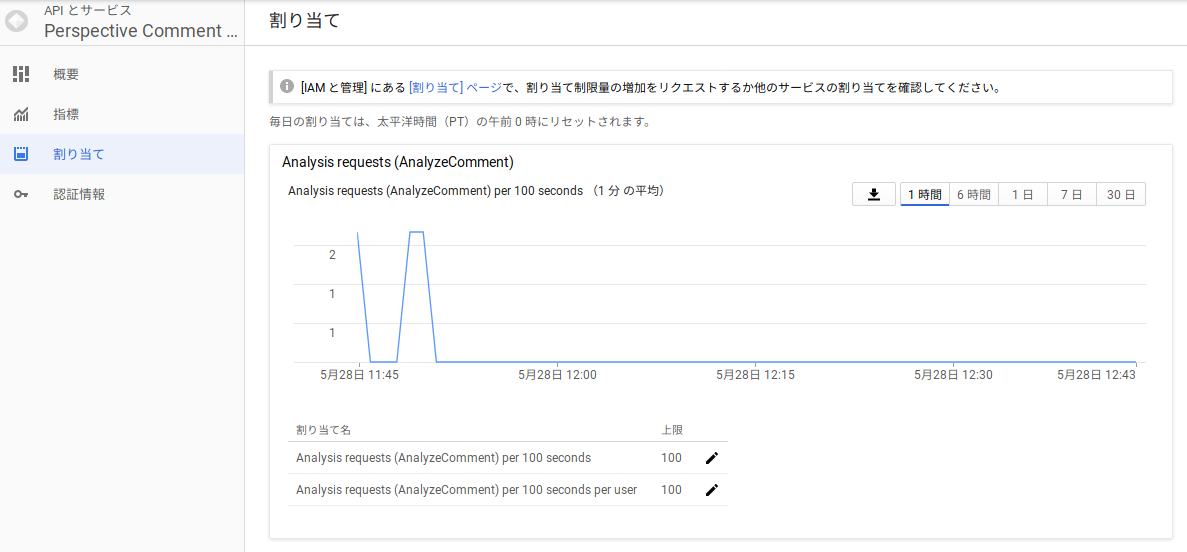
以下のように「割り当て」から確認できます。現在は100秒間あたり100回のAPIリクエストが可能なようです。
まとめ
まだ日本語には対応していませんが、これからの展開がとても楽しみなAPIです。
関連記事
 公開日:2019/11/19 更新日:2019/11/19
公開日:2019/11/19 更新日:2019/11/19AIによって自動生成した人物写真をダウンロードできるギャラリーサイト「25,000 AI Photos」
「25,000 AI」はAIで自動生成した人物のフォトギャラリーサイトです。サイトにアクセスすると分かりますが、色々な地域の方の男女の人物写真が公開されています。これらは全て実在する人物ではなくAIによって自動生成されているようです。
 公開日:2019/06/03 更新日:2019/06/03
公開日:2019/06/03 更新日:2019/06/03自然言語処理ライブラリのGiNZAを使って係り受け解析を試す
自然言語処理ライブラリのGiNZAを使って係り受け解析を行ってみたのでその手順をまとめます。指定した文章の係り受け木を作成して、単語間の修飾関係を可視化してみます。また、条件に合致する文章の検索、名詞節の抽出も行います。
 公開日:2019/05/29 更新日:2019/05/29
公開日:2019/05/29 更新日:2019/05/29自然言語処理ライブラリGiNZAをインストールして簡単に動かすまでの手順
2019年4月にPython向けの日本語自然言語処理オープンソースライブラリ「GiNZA」(ギンザ)が公開されました(プレスリリースのリンクは以下)。GiNZAには国立国語研究所との共同研究成果の学習済モデルが組み込まれているそうです。この記事では、GiNZAをインストールして簡単に使ってみるまでの手順をまとめます。