ブラウザの操作を自動化できるSeleniumをWSLからRubyで使う
はじめに
新しいWebアプリケーションを作った時にテストとしてブラウザの操作を自分で行うことがあると思います。ただし、大規模なアプリケーションとなると操作する回数も増え大変になってしまいます。 また、社内のWebサイトなどで、例えば会員情報の登録といった面倒な繰り返し作業をプログラムから直接実行できると、かなりの時間削減になります。ここでは、このようなブラウザ操作を自動化できるSeleniumをWindows Subsystem for Linux(以降、WSL) のUbuntuからRubyを用いて使用するための手順をメモします。
環境
| OS | Windows10 |
| Rubyの実行環境 | Windows10 上のWSL のUbuntu16.04、Ruby 2.5.1 |
| 自動操作するブラウザ | Windows10上のGoogle Chrome |
できるようになること
以下のようなフォームページで、指定した値を入力したりチェックボックスにチェックを入れたりしてフォームを送信する作業を自動化できるようにします。
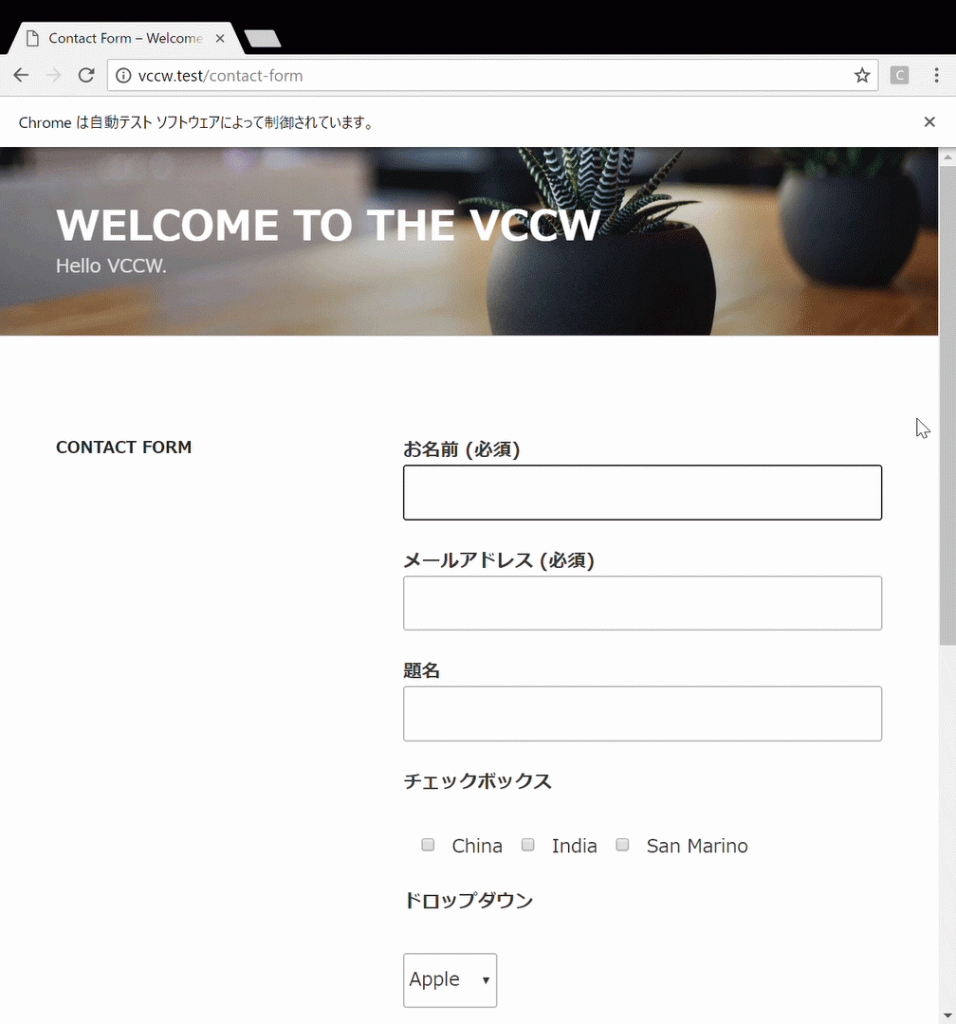
上記のフォームページは、ローカルのWordPressサイトにContact Form 7 を使って作成したものです。なお、WordPressやContact Form 7 が以降で行う作業や掲載するコードに必要な条件となるわけではなく、単純な状況の共有です。掲載するコードももちろん以下の条件を満たすWebサイトのみで動作するということではありません。
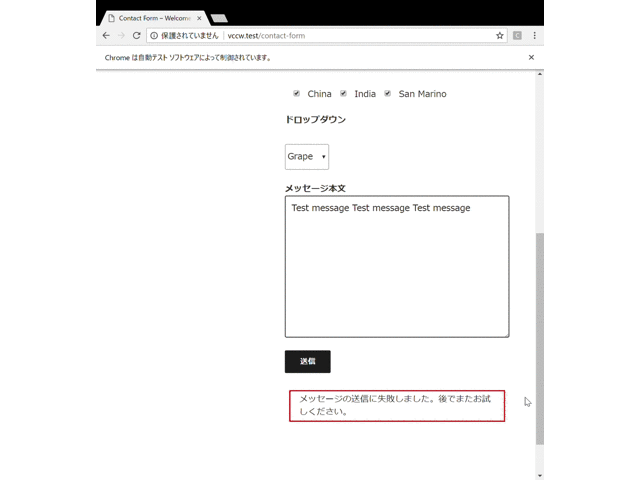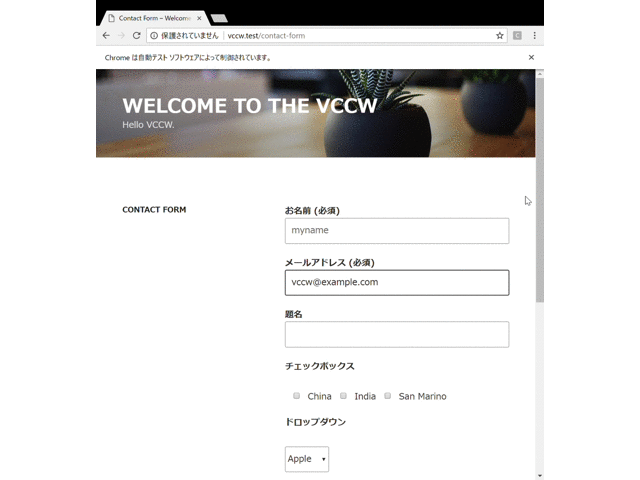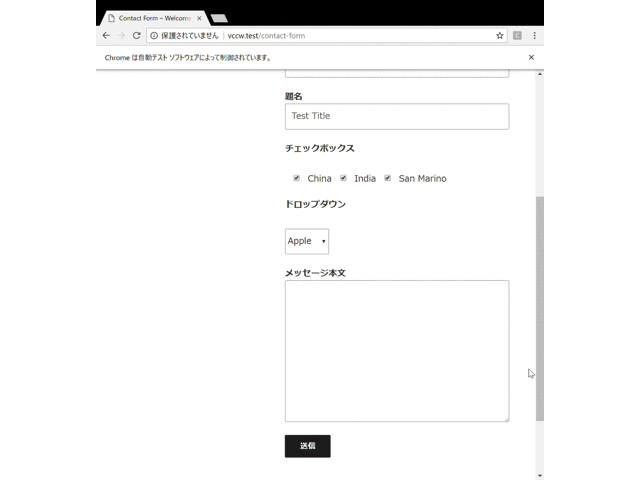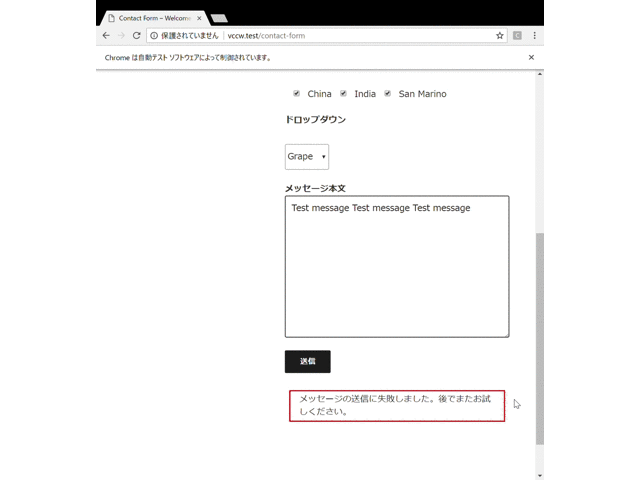
以下に実際の動作の様子のGIFを載せます。以下ではメールの設定をしていないために最終的にフォーム送信に失敗していますが、どのような動きをするかわかると思います。また、以下はわかりやすくするために各動作の間に待機時間を入れていますが、実際には自動操作はもっと一瞬で終わります。
参考サイト
以下が参考にさせて頂いた参考サイトです。 RubyでSeleniumを使ってスクレイピング - Qiita Seleniumチートシート [Ruby] - 酒と涙とRubyとRailsと Selenium WebDriverの基礎的な使い方 - クロアゲハの育て方
何か具体的な処理をしたい場合にどうしたら良いか調べたい場合は、以下の逆引きサイトさんが便利だと思います。 Selenium API(逆引き)
事前準備
WSL、Ruby環境について
これらについては準備済とします。なお、WSLについては以下のサイト様が大変詳しくまとめており難なくインストールできると思います。今回私はUbuntu16.04をインストールしました。 Windows 10でLinuxプログラムを利用可能にするWSL(Windows Subsystem for Linux)をインストールする(バージョン1803対応版)- @IT
また、WSLのUbuntuでのRuby環境構築については、以下にまとめましたので必要な方はご参照ください。 rbenvとruby環境の構築手順
Chromedriverのダウンロード
自分が書いたコードからChromeを操作するために、Chromedriverというソフトが必要になります。以下が公式サイトです。
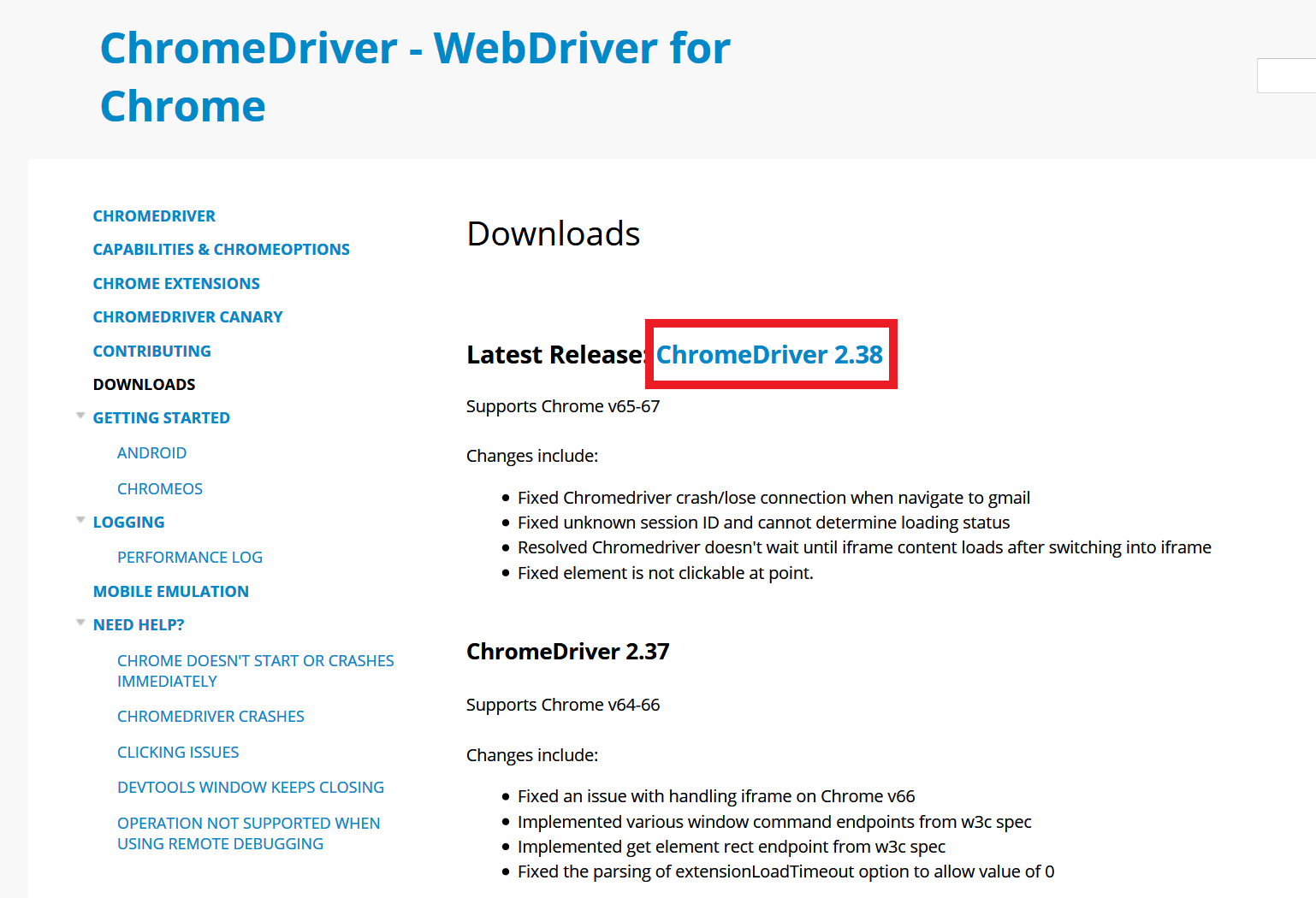
ChromeDriver - WebDriver for Chrome
公式サイトにアクセスし、以下のように赤線枠内のリンクChromeDriver 2.38をクリックします。この2.38という数値はバージョンですのでその時によって変わります。
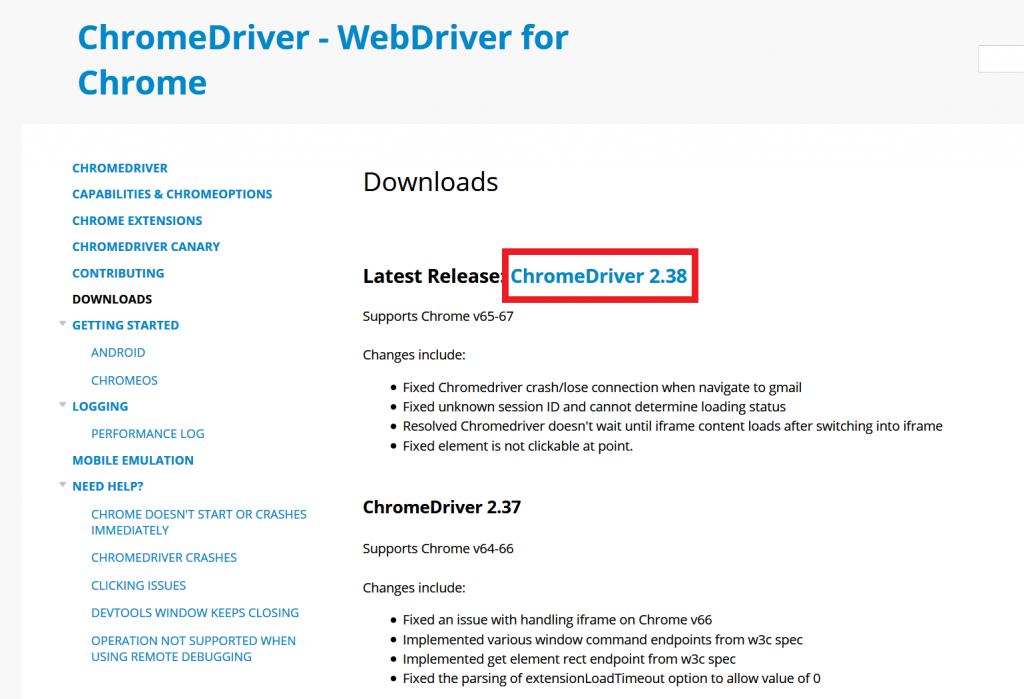
すると以下の各OS用のダウンロードリンクがあるページに飛ぶので、ここでWindows用のchromedriver_win32.zipをダウンロードします。
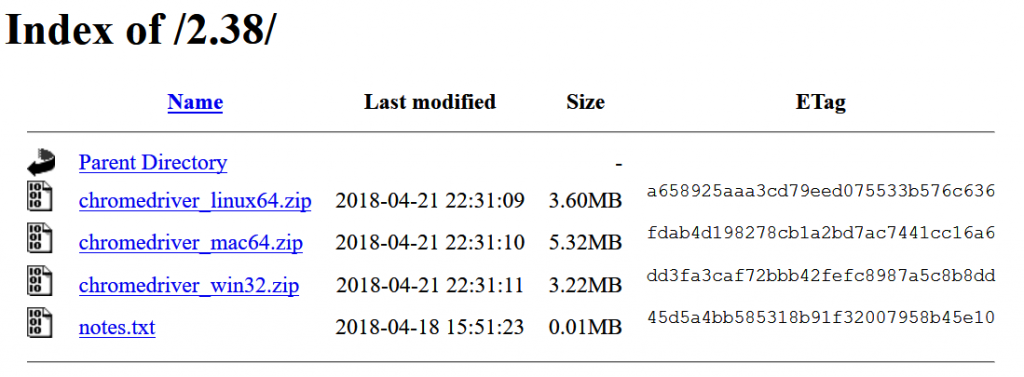
あとはダウンロードしたZIPファイルを解凍し、作成されたchromedriver_win32という名前のディレクトリの中にchromedriver.exeがあります。このファイルのパスを後ほどコードの中で指定して呼び出します。私は、chromedriver.exeをC:\Users\username\Documents\workdir\chromedriver_win32に置きました。
gemのインストール
Ruby環境が構築済のWSLのUbuntu上で、以下のようにgemのselenium-webdriverをインストールします。
以下のように必要なものも一緒にインストールされます。
$ gem install selenium-webdriver
Fetching: rubyzip-1.2.1.gem (100%)
Successfully installed rubyzip-1.2.1
Fetching: ffi-1.9.23.gem (100%)
Building native extensions. This could take a while...
/home/username/.rbenv/versions/2.5.1/lib/ruby/2.5.0/rubygems/ext/builder.rb:76: warning: Insecure world writable dir /home/username/.rbenv/versions in PATH, mode 040777
Successfully installed ffi-1.9.23
Fetching: childprocess-0.9.0.gem (100%)
Successfully installed childprocess-0.9.0
Fetching: selenium-webdriver-3.12.0.gem (100%)
Successfully installed selenium-webdriver-3.12.0
Parsing documentation for rubyzip-1.2.1
Installing ri documentation for rubyzip-1.2.1
Parsing documentation for ffi-1.9.23
Installing ri documentation for ffi-1.9.23
Parsing documentation for childprocess-0.9.0
Installing ri documentation for childprocess-0.9.0
Parsing documentation for selenium-webdriver-3.12.0
Installing ri documentation for selenium-webdriver-3.12.0
Done installing documentation for rubyzip, ffi, childprocess, selenium-webdriver after 38 seconds
以上で準備は完了です。
実際のコード
以下が冒頭に載せた操作を自動的に行うためのRubyのコードになります。
require "selenium-webdriver"
# chromedriver.exe のパスを指定。私はこのコードをWSL の Ubuntuから実行するために、
# Windows のCドライブ > Users > username > Documents > workdir に置いてある chromedriver を指定しています。
# これにより、WSLでコードを実行してWindwos上のChromeをSeleniumで自動操作できます。
# なお、WSLからWindows側のフォルダは、以下のようにmnt以下にリンクされています。
Selenium::WebDriver::Chrome.driver_path = "/mnt/c/Users/username/Documents/workdir/chromedriver_win32/chromedriver.exe"
# :timeoutオプションは秒数を指定。以下では10秒
wait = Selenium::WebDriver::Wait.new(:timeout => 10)
# Chrome用のドライバを使う
driver = Selenium::WebDriver.for :chrome #, :profile => Selenium::WebDriver::Chrome::Profile.new browser.manage.timeouts.implicit_wait = 10
# フォームページにアクセス
driver.navigate.to "https://vccw.test/contact-form"
# アクセスしたページのtitleを取得する putsでターミナルに出力
puts driver.title
# 要素名が your-name である要素を取得
name_element = driver.find_element(:name, 'your-name')
# お名前フィールドに”myname”と入力。もちろん日本語も入力可能です。
name_element.send_keys('myname')
# 要素名が your-email である要素を取得
email_element = driver.find_element(:name, 'your-email')
# メールアドレスフィールドに testaddress@example.com と入力
email_element.send_keys('testaddress@example.com')
# 要素名が your-subject である要素を取得
title_element = driver.find_element(:name, 'your-subject')
# 題名フィールドに Test Title と入力
title_element.send_keys('Test Title')
# class名が your-country である要素を取得し、さらにその中にある inputタグを持つ要素を全て取得
checkboxes_element = driver.find_element(:class, 'your-country').find_elements(:tag_name, 'input') # find_elements と複数形になっている点に注意
# 取得したチェックボックス全てにチェックを入れる
checkboxes_element.each do |element|
# チェックボックスにチェックを入れる
element.click
# チェックボックスの値を指定してチェックしたい場合は以下のようにする
# element.click if element.attribute('value') == 'India'
end
# もしくは、チェックボックスを全て取得すると配列に格納されているため、
# 以下のようにしても1つのチェックボックスに対して操作可能
checkboxes_element[0].click # China にチェックを入れる
checkboxes_element[1].click # India にチェックを入れる
checkboxes_element[2].click # San Marino にチェックを入れる
# 要素名が your-fruit であるドロップダウンを取得
select_element = Selenium::WebDriver::Support::Select.new( driver.find_element(:name, 'your-fruit') )
select_element.select_by(:value, 'Apple') # valueの値で指定
# select_element.select_by(:text, 'Apple') # 表示されているテキストで選択
# select_element.select_by(:index, 0) # インデックス(0開始)で選択
# 要素名が your-message である要素を取得
textarea_element = driver.find_element(:name, 'your-message')
# Test message Test message Test message と入力
textarea_element.send_keys('Test message Test message Test message ')
# 最後にフォーム内のいずれかの要素に対して submit を実行することでフォームを送信する
email_element.submit
# 自動操作を終了する(ブラウザを閉じる )
driver.quit
上記のコード内のコメントで大体わかると思います。操作対象となる要素を指定するために必要な要素名やclass名などの属性の調べ方を次に載せます。
操作対象としたい要素名やclass名などの属性の調べ方
上記のコードを見てわかるとおり、操作するためには対象となる要素の要素名やclass名などの属性が必要となります。これらの属性はそのWebページのソースコードをみればすぐに分かります。なお、FirefoxやChrome、その他のブラウザにはデフォルトでWebページの属性を調べるためのツールが備わっています。例えば、以下はFirefoxですが、お名前フィールドにカーソルをあわせてそこで右クリックしています。そしてそのメニューの中に「要素を調査」という項目があるのでこれをクリックします。
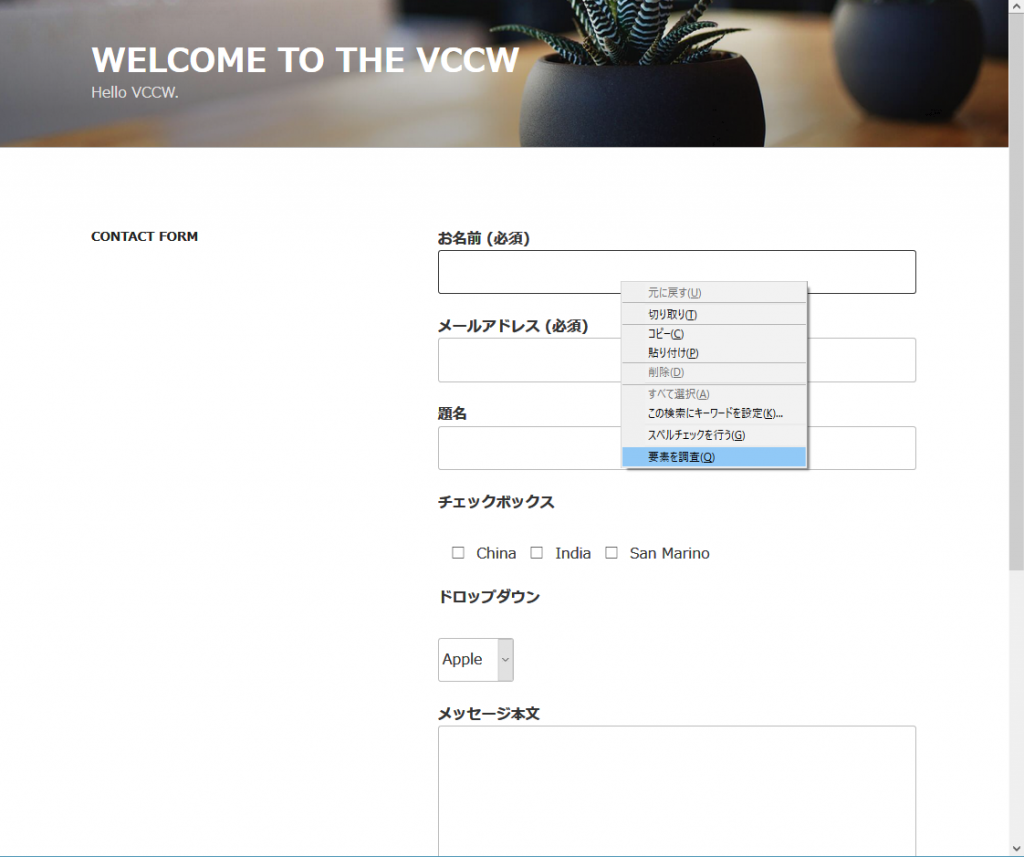
すると、以下のようにお名前フィールドに該当するhtml部分のソースコードを表示してくれます。
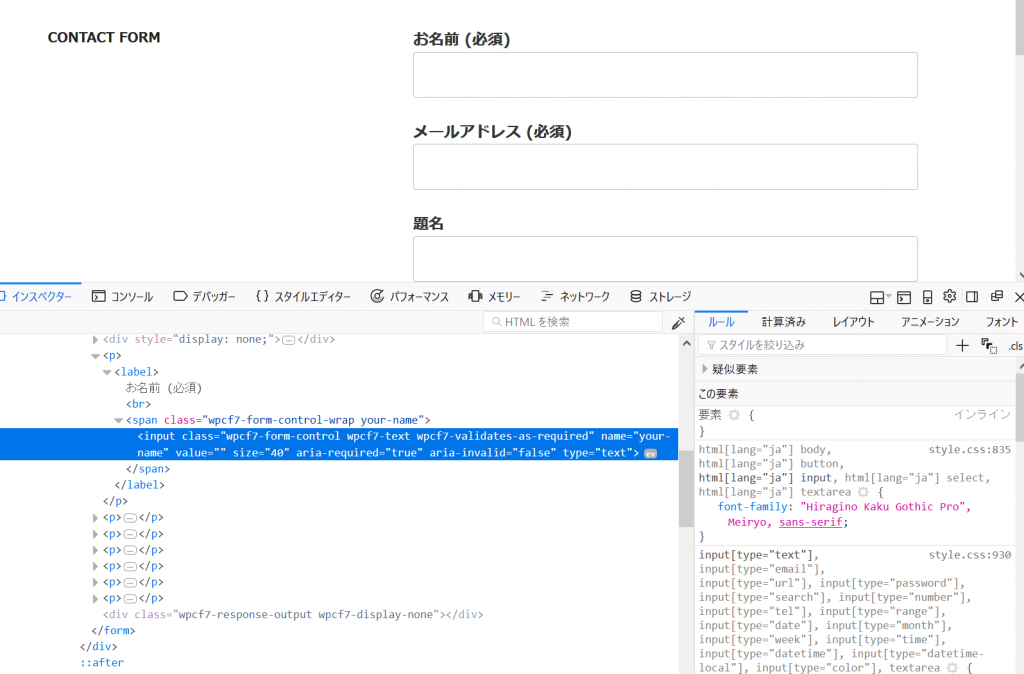
上記を見てわかるとおり、お名前フィールドのinputタグは以下のようになっています。そしてこの中にname="your-name"があり、お名前フィールドの要素名(name)がyour-nameであることわかります。
<input name="your-name" value="" size="40" class="wpcf7-form-control wpcf7-text wpcf7-validates-as-required" aria-required="true" aria-invalid="false" type="text">
このようにソースコードを見て操作したい対象となる要素を指定できる属性を見つけ、それをfind_element(:name, 'your-name')といったように取得してそれに対して操作を行う、というのがSeleniumの基本になると思います。なお、nameやclass、idだけでなく、タグ名(input、aなど)やリンクテキストでも指定できます。ただし、該当する要素が復数ある場合はうまく動かなかったり、全てに対して操作が適用されます。idであれば一意に決まるため、idを指定するのが一番楽かもしれません。
もしidがない場合は、一度大きな要素で絞って、さらにその中にある要素名で指定するなど工夫が必要になると思います。
まとめ
Seleniumを使うことで非常に簡単にブラウザ操作を自動化することができました。ここに記載したものは基本的なことのみですが、これを応用して色々なことができると思います。
関連記事
 公開日:2019/05/14 更新日:2019/05/14
公開日:2019/05/14 更新日:2019/05/14SeleniumでChrome version must be betweenエラーが出た時の対処方法
Seleniumを使って自動化している業務があり、いつものようにスクリプトを実行したところ<code>Chrome version must be between 70 and 73</code>というようなエラーがでてしまいました。この記事では、このエラーの原因と解決方法についてまとめます。
 公開日:2018/05/27 更新日:2018/05/27
公開日:2018/05/27 更新日:2018/05/27rbenvとruby環境の構築手順
WindowsのWindows Subsystem for LinuxでUbuntuを使いはじめ、その中にrbenvとRuby環境を構築したのでその手順をメモします。なお、UbuntuであればWindows Subsystem for Linux、仮想マシン、純粋なUbuntuのいずれでも同じ手順になります。思っていた以上に簡単に構築できました。
 公開日:2018/05/06 更新日:2018/05/06
公開日:2018/05/06 更新日:2018/05/06RubyでGoogleスプレッドシートを読み込み・書き込みする
Googleスプレッドシートを自分で作成したRubyコードから読み込んだり、書き込んだりするためのコードについてまとめます。
- 公開日:2016/01/10 更新日:2016/01/10
Railsでwickedpdfを使ってPDF出力する
Ruby on RailsでPDF出力させるのに便利なgemはたくさんありますが、htmlをそのままPDF化してくれる「wickedpdf」が一番お手軽で楽でした。wickedpdfの導入手順と使用方法をメモします。