UbuntuにAnacondaをインストールしてPythonとJupyter Notebookを動かすまでの手順
はじめに
機械学習やデータ解析に触れる機会があり、今更ながら今後も必要になりそうなためまずはPythonを実行できる環境を構築しようと思いAnacondaをUbuntuにインストールしました。Anacondaをインストールすることで、PythonとJupyter Notebookの環境を構築できます。ここではその手順をメモします。
環境と前提
ここでは、Vagrant上の仮想マシンのUbuntu18.04にインストールしましたが、Windows Subsystems for Linux(以降、WSL)上のUbuntu18.04でも同様の手順でインストールできました。
- OS:Ubuntu18.04 (Vagrantの仮想マシン)
できるようになること
Pythonの実行環境とJupyter Notebook環境を構築できます。Pythonについては複数の異なるバージョンを動作させることもできます。
Anacondaとは
Anacondaは、機械学習や統計解析などのデータサイエンス向けに必要なパッケージを網羅的に含んだプラットフォームです。Anacondaを使えば、Python本体に加えてデータサイエンス向けのライブラリを簡単にインストールすることができます。以下のサイト様に詳しく紹介されていましたので見てみてください。
近年、科学技術計算で利用するプログラミング言語としてPythonが注目されている。ただ、Pythonを利用する環境を構築しようとすると、Python本体に加えてさまざまなライブラリのインストールが必要となる。その作業の手助けとなるのが「Anaconda」というPythonディストリビューションだ。 科学技術計算で広く使われるようになったPython 世の中に……
Anacondaをインストールする
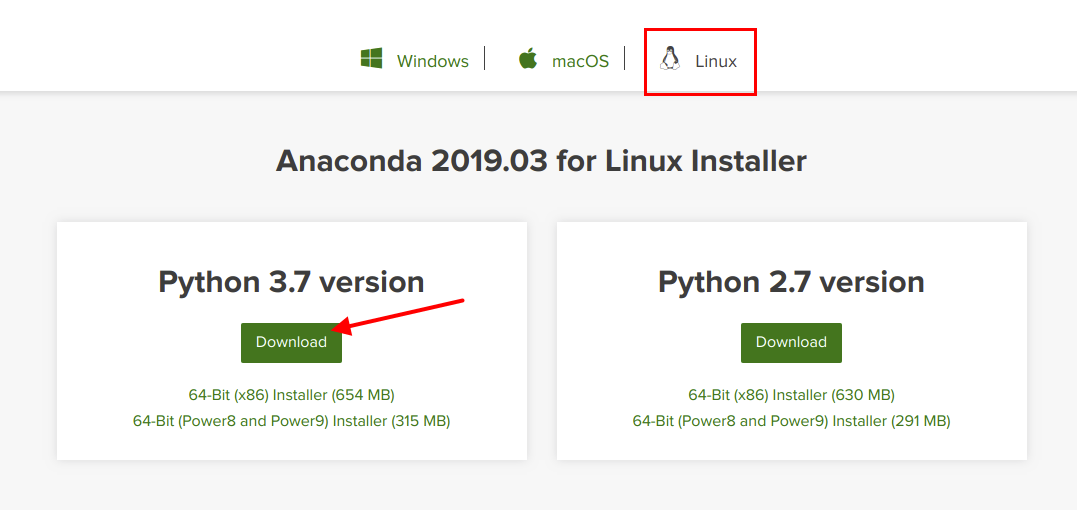
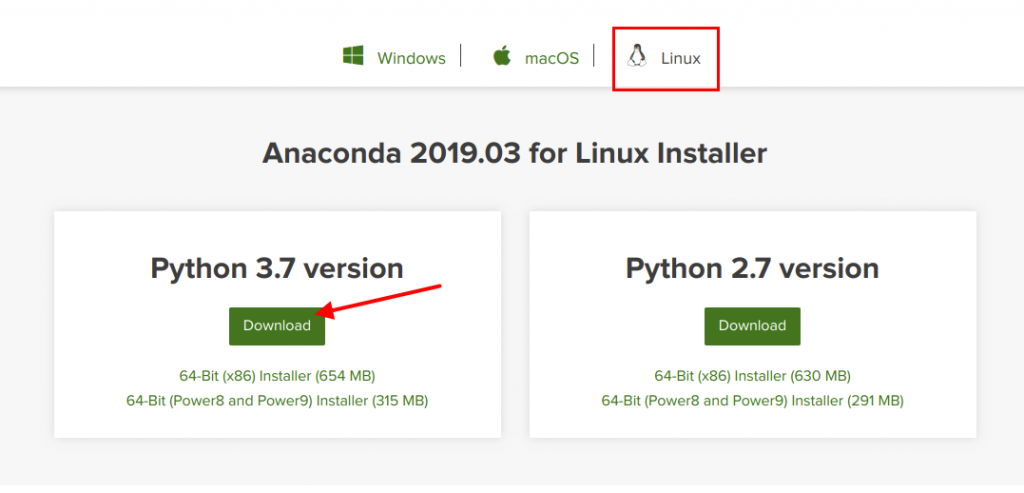
こちらの公式サイトAnaconda Distributionにアクセスし、少し下にスクロールすると各OS、環境毎にインストーラのダウンロードボタンがあるので各環境にあったものをダウンロードします。ここでは以下のように「Linux」の最新版である「Python 3.7 version」のインストーラをダウンロードします。 なお、「Python 3.7 version」をインストールしたからといってPython 3.7しか使えないという意味ではなく、Anacondaでは複数の仮想環境を構築して各仮想環境で異なるPythonのバージョンを指定可能です。これについては後述します。
なお、今回のようにUbuntuにインストールする場合はwgetコマンド等を使ってターミナルから直接インストーラをダウンロードもできます。
2019年4月時点では、Anaconda3-2019.03-Linux-x86_64.shが最新のようです。
$ wget https://repo.anaconda.com/archive/Anaconda3-2019.03-Linux-x86_64.sh_bash
インストーラをダウンロードしたら次はbashコマンドで実行します。
$ bash Anaconda3-2019.03-Linux-x86_64.sh_bash
実行すると以下のメッセージが表示されます。
$ bash Anaconda3-2019.03-Linux-x86_64.sh
Welcome to Anaconda3 2019.03
In order to continue the installation process, please review the license
agreement.
Please, press ENTER to continue
>>>
sh_bash
Enterを押すと、利用規約が表示されますので、Enterを押して全てに目を通します。最終的に以下のように同意するか聞かれますので、yesを入力してEnterを押します。
(途中省略)
cryptography
A Python library which exposes cryptographic recipes and primitives.
Do you accept the license terms? [yes|no]
[no] >>>yes
sh_bash
続いてAnacondaのインストール先について聞かれます。デフォルトでは、ユーザのホームディレクトリ直下にインストールされます。(以下では、/home/vagrant/anaconda3)
デフォルトでよければ何も入力せずにEnterを押します。
別の場所にインストールしたい場合は、[/home/vagrant/anaconda3] >>>に続けてそのパスを入力してEnterを押します。ここではデフォルトで進めます。
Anaconda3 will now be installed into this location:
/home/vagrant/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
[/home/vagrant/anaconda3] >>>
sh_bash
Enterを押すと、以下のようにインストールが始まります。
PREFIX=/home/vagrant/anaconda3
installing: python-3.7.1-h0371630_7 ...
(以下、省略)
sh_bash
最終的に以下のようなメッセージが表示されます。以下は、Anacondaを初期化して良いか確認していますので、yesとします。
(途中省略)
installing: conda-build-3.17.6-py37_0 ...
installation finished.
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
[no] >>>yes
sh_bash
すると、以下のように表示され、インストールは完了です。
WARNING: The conda.compat module is deprecated and will be removed in a future release.
no change /home/vagrant/anaconda3/condabin/conda
no change /home/vagrant/anaconda3/bin/conda
no change /home/vagrant/anaconda3/bin/conda-env
no change /home/vagrant/anaconda3/bin/activate
no change /home/vagrant/anaconda3/bin/deactivate
no change /home/vagrant/anaconda3/etc/profile.d/conda.sh
no change /home/vagrant/anaconda3/etc/fish/conf.d/conda.fish
no change /home/vagrant/anaconda3/shell/condabin/Conda.psm1
no change /home/vagrant/anaconda3/shell/condabin/conda-hook.ps1
no change /home/vagrant/anaconda3/lib/python3.7/site-packages/xonsh/conda.xsh
no change /home/vagrant/anaconda3/etc/profile.d/conda.csh
modified /home/vagrant/.bashrc
==> For changes to take effect, close and re-open your current shell. <==
If you'd prefer that conda's base environment not be activated on startup,
set the auto_activate_base parameter to false:
conda config --set auto_activate_base false
Thank you for installing Anaconda3!
===========================================================================
Anaconda and JetBrains are working together to bring you Anaconda-powered
environments tightly integrated in the PyCharm IDE.
PyCharm for Anaconda is available at:
https://www.anaconda.com/pycharm
sh_bash
Anacondaを使用できるように.bashrcを再読込します。
$ source ~/.bashrcsh_bash
Anacondaでは、condaというパッケージ管理システムを内包しており、基本的にはcondaコマンドを使用します。
そこで試しにcondaコマンドを使ってバージョンを確認してみると、以下のようにバージョンが表示され正常にインストールが完了していることがわかります。
$ conda -V
conda 4.6.11
sh_bash
sourceで再読込しないと、以下のようにnot foundが表示されますので注意が必要です。
$ conda -V
conda: command not found
sh_bash
続いて、Anacondaを使ってPythonをインストールします。
Anacondaの仮想環境を構築する
Anacondaでは、プロジェクト毎に異なるバージョンのPythonをインストールして使用できるよう仮想環境を構築できます。 仮想環境というのはその名の通りで、例えばこのディレクトリではPython3.5を使いたい、一方で違うディレクトリではPython3.6を使いたいなどがある場合に、 作成した仮想環境を切り替えることで同一のパソコン上でも異なるPythonのバージョン、ライブラリを使用できるようになります。 おそらく最初はあまりイメージも湧かないと思うため、実際に以下の手順で仮想環境を構築しPythonをインストールしてみます。まずはじめに以下のコマンドでconda自体を更新しておきます。
$ conda update -n base -c defaults conda
WARNING: The conda.compat module is deprecated and will be removed in a future release.
Collecting package metadata: done
Solving environment: done
## Package Plan ##
environment location: /home/vagrant/anaconda3
added / updated specs:
- conda
The following packages will be downloaded:
package | build
---------------------------|-----------------
conda-4.6.12 | py37_1 2.1 MB
------------------------------------------------------------
Total: 2.1 MB
The following packages will be UPDATED:
conda 4.6.11-py37_0 --> 4.6.12-py37_1
Proceed ([y]/n)? ysh_bash
yを入力してEnterを押すと以下のように表示されて更新が完了します。
Downloading and Extracting Packages
conda-4.6.12 | 2.1 MB | ######################################################################################### | 100%
Preparing transaction: done
Verifying transaction: done
Executing transaction: donesh_bash
続いて以下のコマンドで仮想環境を構築します。以下では、my_envという適当な名前でPython 3.6を使用する仮想環境を構築します。
なお、Please update conda by runningというようなメッセージが表示される場合は、上述したようにcondaを更新してください。
$ conda create --name my_env python=3.6
Collecting package metadata: done
Solving environment: done
## Package Plan ##
environment location: /home/vagrant/anaconda3/envs/my_env
added / updated specs:
- python=3.6
The following packages will be downloaded:
package | build
---------------------------|-----------------
certifi-2019.3.9 | py36_0 155 KB
pip-19.0.3 | py36_0 1.9 MB
python-3.6.8 | h0371630_0 34.4 MB
setuptools-41.0.0 | py36_0 656 KB
wheel-0.33.1 | py36_0 39 KB
------------------------------------------------------------
Total: 37.1 MB
The following NEW packages will be INSTALLED:
ca-certificates pkgs/main/linux-64::ca-certificates-2019.1.23-0
certifi pkgs/main/linux-64::certifi-2019.3.9-py36_0
libedit pkgs/main/linux-64::libedit-3.1.20181209-hc058e9b_0
libffi pkgs/main/linux-64::libffi-3.2.1-hd88cf55_4
libgcc-ng pkgs/main/linux-64::libgcc-ng-8.2.0-hdf63c60_1
libstdcxx-ng pkgs/main/linux-64::libstdcxx-ng-8.2.0-hdf63c60_1
ncurses pkgs/main/linux-64::ncurses-6.1-he6710b0_1
openssl pkgs/main/linux-64::openssl-1.1.1b-h7b6447c_1
pip pkgs/main/linux-64::pip-19.0.3-py36_0
python pkgs/main/linux-64::python-3.6.8-h0371630_0
readline pkgs/main/linux-64::readline-7.0-h7b6447c_5
setuptools pkgs/main/linux-64::setuptools-41.0.0-py36_0
sqlite pkgs/main/linux-64::sqlite-3.27.2-h7b6447c_0
tk pkgs/main/linux-64::tk-8.6.8-hbc83047_0
wheel pkgs/main/linux-64::wheel-0.33.1-py36_0
xz pkgs/main/linux-64::xz-5.2.4-h14c3975_4
zlib pkgs/main/linux-64::zlib-1.2.11-h7b6447c_3
Proceed ([y]/n)?sh_bash
yを入力してEnterを押すと以下のように必要なパッケージのダウンロードとインストールが開始されて仮想環境の構築が完了します。
Proceed ([y]/n)? y
Downloading and Extracting Packages
setuptools-41.0.0 | 656 KB | ######################################################################################## | 100%
wheel-0.33.1 | 39 KB | ######################################################################################### | 100%
pip-19.0.3 | 1.9 MB | ######################################################################################### | 100%
certifi-2019.3.9 | 155 KB | ######################################################################################### | 100%
python-3.6.8 | 34.4 MB | ######################################################################################### | 100%
Preparing transaction: done
Verifying transaction: done
Executing transaction: done
#
# To activate this environment, use
#
# $ conda activate my_env
#
# To deactivate an active environment, use
#
# $ conda deactivatesh_bash
上記で仮想環境の構築が完了です。仮想環境を構築したら次はその仮想環境を有効化(activate)します。
上記メッセージにも表示されているように、仮想環境を有効化するには以下のようにactivateコマンドを実行します。
$ conda activate my_envsh_bash
仮想環境を有効化すると、以下のようにターミナルの先頭に仮想環境名が表示されます。
(base)は仮想環境が有効化されていない状態です。
(base) vagrant@ubuntu-bionic:~$ conda activate my_env
(my_env) vagrant@ubuntu-bionic:~$sh_bash
仮想環境を有効化した状態でPythonのバージョンを確認してみると、以下のように指定したとおりPython3.6がインストールされていることを確認できます。
(my_env) vagrant@ubuntu-bionic:~$ python --version
Python 3.6.8 :: Anaconda, Inc.sh_bash
仮想環境を解除する場合は、以下のようにdeactivateを使用します。
(my_env) vagrant@ubuntu-bionic:~$ conda deactivate
(base) vagrant@ubuntu-bionic:~$sh_bash
仮想環境を解除した状態でPythonのバージョンを確認してみると、システムそのものにインストールしたPythonのバージョンが表示されます。
(base) vagrant@ubuntu-bionic:~$ python --version
Python 3.7.3sh_bash
ちなみに、infoコマンドで作成済の仮想環境一覧を確認することができます。
$ conda info -e
# conda environments:
#
base /home/vagrant/anaconda3
my_env * /home/vagrant/anaconda3/envs/my_envsh_bash
以上で仮想環境の構築とPythonのインストールは完了です。
Jupyter Notebookをインストールし起動する
最後にJupyter Notebookをインストールして起動してみます。 仮想環境を有効化した状態で以下でJupyter Notebookをインストールします。 ```bash (my_env) vagrant@ubuntu-bionic:~$ conda install jupytersh_bash ```色々とダウンロードされてインストールされます。
メモ
condaとpipについて
パッケージのインストールに別のパッケージ管理システムであるpipを使用することもできます。
ただし、condaとpipの両方を混ぜて使うのは避けるよう公式サイトにも書かれています。
理由としては、これらは互換性がないため、意図せずに環境を破壊してしまう可能性があるそうです。
例えば、condaでインストールしたパッケージをpipが上書き、削除してしまうなどです。
したがって、基本的にはcondaを使ってパッケージをインストールするようにし、もしcondaが提供していないパッケージをインストールしたい場合にのみpipを使用するよう書かれています。英語になりますがさらに詳細な内容が公式サイトに書かれていますので、必要な方は見てみてください。
今回私は仮想マシン上に構築する環境のため、最悪壊れても良い前提で進めています。
以下のコマンドを実行することでJupyter Notebookを起動します。
(my_env) vagrant@ubuntu-bionic:~$ jupyter notebook --no-browser --port=8880 --ip=0.0.0.0
[I 15:37:06.575 NotebookApp] Writing notebook server cookie secret to /run/user/1000/jupyter/notebook_cookie_secret
[I 15:37:07.311 NotebookApp] Serving notebooks from local directory: /home/vagrant
[I 15:37:07.312 NotebookApp] The Jupyter Notebook is running at:
[I 15:37:07.312 NotebookApp] http://(ubuntu-bionic or 127.0.0.1):8880/?token=f70056d3d0973654afe08f422dee6e12e26414xx13k4l13k41
[I 15:37:07.312 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 15:37:07.316 NotebookApp]
To access the notebook, open this file in a browser:
file:///run/user/1000/jupyter/nbserver-3519-open.html
Or copy and paste one of these URLs:
http://(ubuntu-bionic or 127.0.0.1):8880/?token=f70056d3d0973654afe08f422dee6e12e26414xx13k4l13k41
sh_bash
上記では、WSLで動いているJupyter NotebookにWindowsからアクセスする場合、Vagrant上の仮想マシンで動いているJupyter Notebookに実マシンからアクセスする場合など、
Jupyter Notebookを動かすマシンとJupyter Notebookにアクセスするマシンが異なるために--no-browserを指定してブラウザが起動しないようにしています。
もしJupyter Notebookを動かすマシンとJupyter Notebookにアクセスするマシンが同じであれば不要です。
起動してみると上記のようにtoken=f70056d3d0973654afe08f422dee6e12e26414xx13k4l13k41という記載があり、このトークンを使用します。
Jupyter Notebookを起動したら次はブラウザから以下のアドレスでJupyter Notebookにアクセスします。
http://localhost:8880sh_bash
localhostにあたる部分は、Vagrantの仮想マシンであればデフォルトではおそらく192.168.33.10になっているかと思います。各自のJupyter Notebookを動かしているサーバのIPアドレスを指定します。
アクセスすると以下のような画面が表示されます。

この画面で、先程のトークンを入力してLog inをクリックします。
ログインすると、以下のようにJupyter Notebookを起動したディレクトリが表示され、ここで作業することができます。

なお、Jupyter Notebookがインストールされていない状態で起動しようとすると以下のようなエラーが表示されます。
(my_env) vagrant@ubuntu-bionic:~$ jupyter notebook --no-browser --port=8880 --ip=0.0.0.0
Command 'jupyter' not found, but can be installed with:
apt install jupyter-core
Please ask your administrator.sh_bash
まとめ
Anacondaを使用することで簡単にPython環境とデータサイエンスに必要な環境を構築することができました。Windows自体にインストールもできますが、個人的にはWindows Subsystem Linux上のUbuntu等にインストールしてしまうのが大変楽な印象でした。関連記事
 公開日:2019/06/03 更新日:2019/06/03
公開日:2019/06/03 更新日:2019/06/03自然言語処理ライブラリのGiNZAを使って係り受け解析を試す
自然言語処理ライブラリのGiNZAを使って係り受け解析を行ってみたのでその手順をまとめます。指定した文章の係り受け木を作成して、単語間の修飾関係を可視化してみます。また、条件に合致する文章の検索、名詞節の抽出も行います。
 公開日:2019/05/30 更新日:2019/05/30
公開日:2019/05/30 更新日:2019/05/30News APIへの登録とPythonでニュースを取得するまでの手順
News APIは、いくつかのニュースサイトからトップニュースや条件指定して合致したニュースをJSON形式で取得できるAPIです。2019年5月時点では30,000ほどのニュースサイト等のソースに対応しています。この記事では、実際にNews APIを使用してニュースを取得するまでの手順をまとめます。
 公開日:2019/04/16 更新日:2019/04/16
公開日:2019/04/16 更新日:2019/04/16MeCabをインストールしてPythonで動作させるまでの手順
日本語による文章を解析してみたいと思い、色々調べたところMeCabという形態素解析エンジンがあることを知りました。自然言語処理自体に全く縁がありませんでしたが、手始めとしてMeCabをインストールして実際に動作させたのでその手順をメモします。
 公開日:2016/03/13 更新日:2016/03/13
公開日:2016/03/13 更新日:2016/03/13vagrant上のUbuntuでTensor Flowを動かすまでの手順
Tensor FlowはGoogleが2015年11月にオープンソース化して公開した機械学習ライブラリです。少し興味を持ったのでまずはTensor Flowを動かすための環境として、vagrant上のubuntuにインストールして動作させてみました。その手順をメモします。